
дёҠжңҹжҲ‘们и°ҲеҲ°дәҶзі»з»ҹз»јиҝ°е’ҢMetaеҲҶжһҗзҡ„еёёз”ЁиҪҜ件е·Ҙе…·пјҢд»ҠеӨ©жҲ‘们е°ұжқҘйҮҚзӮ№и§ЈжһҗдёҖдёӢMetaеҲҶжһҗзҡ„ж–№жі•жӯҘйӘӨгҖӮ
MetaеҲҶжһҗжҳҜеҜ№е…·еӨҮзү№е®ҡжқЎд»¶зҡ„гҖҒеҗҢиҜҫйўҳзҡ„иҜёеӨҡз ”з©¶з»“жһңиҝӣиЎҢз»јеҗҲзҡ„дёҖзұ»з»ҹи®Ўж–№жі•пјҢйҖҡеёёз”ЁдәҺж”ҜжҢҒз ”з©¶з»Ҹиҙ№з”іиҜ·пјҢжҢҮеҜјдёҙеәҠе®һи·өе’ҢеҒҘеә·ж”ҝзӯ–гҖӮ
з”ұдәҺз”ЁдәҺи®Ўз®—MetaеҲҶжһҗзҡ„иҪҜ件е’Ңи„ҡжң¬зҡ„е№ҝжіӣеҸҜз”ЁжҖ§пјҢMetaеҲҶжһҗеҸҜиғҪдјҡеңЁе·ІеҸ‘иЎЁз ”з©¶йўҶеҹҹдёӯд»ҘжҢҮж•°еўһй•ҝзҡ„еҪўејҸжҢҒз»ӯдёӢеҺ»пјҢжҜ”еҰӮеңЁеҝғзҗҶ科еӯҰдёӯзҡ„иҝҗз”ЁпјҲеӣҫ1пјүгҖӮгҖӮ
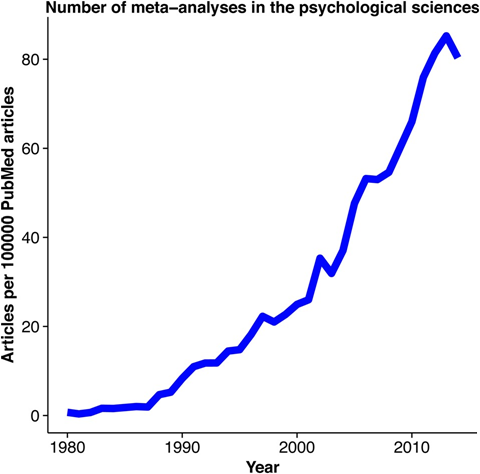
еӣҫ1. еҝғзҗҶ科еӯҰдёӯзҡ„MetaеҲҶжһҗ
жң¬ж–Үзҡ„зӣ®зҡ„жҳҜжҸҗдҫӣдёҖдёӘз®Җзҹӯзҡ„MetaеҲҶжһҗйқһжҠҖжңҜжҖ§е…Ҙй—ЁпјҢд»ҘжҢҮеҜјиҜ»иҖ…е®ҢжҲҗд»Һйў„жіЁеҶҢеҲ°з»“жһңеҸ‘еёғзҡ„ж•ҙдёӘиҝҮзЁӢгҖӮ
еңЁеҝғзҗҶеӯҰдёӯеҸ‘иЎЁжңҖеӨҡMetaеҲҶжһҗзҡ„25з§ҚжңҹеҲҠдёӯпјҢи¶…иҝҮдёҖеҚҠе»әи®®дҪҝз”ЁPRISMAжҢҮеҚ—пјҢжҲ–зӣёе…іMetaеҲҶжһҗжҠҘе‘Ҡж ҮеҮҶпјҲMARS)пјҲеӣҫ2пјүгҖӮеӣ жӯӨпјҢжң¬ж–Үе°Ҷжј”зӨәеҰӮдҪ•жҢүз…§PRISMAжҢҮеҚ—иҝӣиЎҢMetaеҲҶжһҗгҖӮжң¬ж–ҮжҸҗдҫӣдәҶдёҖдёӘиЎҘе……зҡ„Rи„ҡжң¬жқҘжј”зӨәи®әж–ҮдёӯжҸҸиҝ°зҡ„жҜҸдёӘеҲҶжһҗжӯҘйӘӨпјҢиҜҘжӯҘйӘӨеҫҲе®№жҳ“йҖӮеә”з ”з©¶дәәе‘ҳз”ЁдәҺ他们иҮӘе·ұзҡ„ж•°жҚ®еҲҶжһҗгҖӮ
еҗҢж—¶иҝҳејәи°ғдәҶMetaеҲҶжһҗеЈ°жҳҺе’Ңйў„жіЁеҶҢзҡ„йҮҚиҰҒжҖ§пјҢд»ҘжҸҗй«ҳйҖҸжҳҺеәҰ并帮еҠ©йҒҝе…Қж„ҸеӨ–йҮҚеӨҚгҖӮжӣҙеҘҪең°зҗҶи§ЈиҝҷдёӘе·Ҙе…·дёҚд»…еҸҜд»Ҙеё®еҠ©з§‘еӯҰ家иҝӣиЎҢ他们иҮӘе·ұзҡ„MetaеҲҶжһҗпјҢиҝҳеҸҜд»Ҙ改善他们еҜ№е·ІеҸ‘иЎЁMetaеҲҶжһҗзҡ„иҜ„дј°гҖӮ
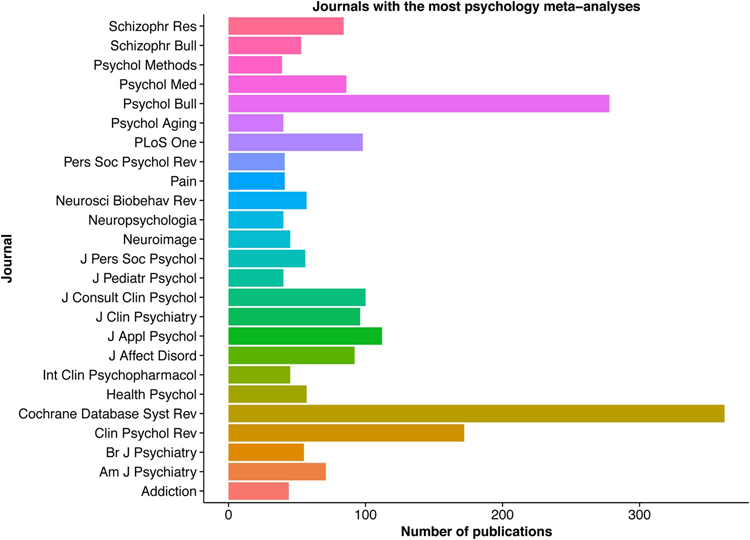
еӣҫ2. еҸ‘иЎЁжңҖеӨҡMetaеҲҶжһҗзҡ„еҝғзҗҶеӯҰжңҹеҲҠ
дёҖгҖҒMetaеҲҶжһҗеЈ°жҳҺе’Ңйў„жіЁеҶҢ
йў„е…Ҳзҷ»и®°MetaеҲҶжһҗеЈ°жҳҺзҡ„дё»иҰҒеҘҪеӨ„жҳҜеҸҢйҮҚзҡ„гҖӮйҰ–е…ҲпјҢйў„жіЁеҶҢиҝҮзЁӢиҝ«дҪҝз ”з©¶дәәе‘ҳдёәзү№е®ҡз ”з©¶й—®йўҳеҲ¶е®ҡз ”з©¶зҗҶи®әеҹәзЎҖпјӣе…¶ж¬ЎпјҢйў„жіЁеҶҢйҖҡиҝҮжҸҗдҫӣе…ҲйӘҢеҲҶжһҗзӣ®зҡ„зҡ„иҜҒжҚ®жңүеҠ©дәҺйҒҝе…ҚеҒҸеҖҡгҖӮ
еңЁMetaеҲҶжһҗзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘеңЁе·ІзҹҘз»“жһңд»ҘйҖӮеә”е№ҝеҸ—ж¬ўиҝҺзҡ„з»“жһңжҲ–еҮҸе°‘еҸ‘иЎЁеҒҸеҖҡзҡ„иҜҒжҚ®еҗҺи°ғж•ҙе…ҘйҖүж ҮеҮҶгҖӮPRISMAпјҲPRISMA-PпјүжҢҮеҚ—жҸҗдҫӣдәҶжҠҘе‘ҠMetaеҲҶжһҗеЈ°жҳҺзҡ„жЎҶжһ¶гҖӮиҝҷдәӣжҢҮеҚ—е»әи®®еЈ°жҳҺеә”иҜҘеҢ…жӢ¬д»ҘдёӢиҜҰз»ҶдҝЎжҒҜпјҢеҰӮз ”з©¶еҺҹзҗҶпјҢз ”з©¶иө„ж јж ҮеҮҶпјҢжЈҖзҙўзӯ–з•ҘпјҢи°ғиҠӮеҸҳйҮҸпјҢеҒҸеҖҡйЈҺйҷ©е’Ңз»ҹи®Ўж–№жі•гҖӮ
з”ұдәҺMetaеҲҶжһҗжҳҜиҝӯд»ЈиҝҮзЁӢпјҢеЈ°жҳҺеҸҜиғҪдјҡйҡҸзқҖж—¶й—ҙзҡ„жҺЁз§»иҖҢеҸ‘з”ҹеҸҳеҢ–гҖӮе®һйҷ…дёҠпјҢи¶…иҝҮ20пј…зҡ„MetaеҲҶжһҗж”№еҸҳдәҶеҺҹе§ӢеЈ°жҳҺгҖӮйҖҡиҝҮеңЁеҲҶжһҗд№ӢеүҚи®°еҪ•еЈ°жҳҺпјҢиҝҷдәӣеҸҳеҢ–жҳҜдёҖзӣ®дәҶ然зҡ„гҖӮдёҺеҺҹе§ӢеЈ°жҳҺзҡ„д»»дҪ•еҒҸе·®йғҪеҸҜд»ҘеңЁж–Үз« зҡ„ж–№жі•йғЁеҲҶдёӯиҜҙжҳҺгҖӮ
MetaеҲҶжһҗеҸҜд»ҘеңЁPROSPEROж•°жҚ®еә“дёӯжіЁеҶҢгҖӮиҷҪ然еӨ§еӨҡж•°жңҹеҲҠжІЎжңүжҳҺ确规е®ҡMetaеҲҶжһҗжіЁеҶҢжҳҜдёҖйЎ№иҰҒжұӮпјҢдҪҶи®ёеӨҡжңҹеҲҠиҰҒжұӮжҸҗдәӨPRISMAжЈҖжҹҘиЎЁпјҢе…¶дёӯеҢ…жӢ¬еЈ°жҳҺе’Ңз ”з©¶жіЁеҶҢгҖӮжӯӨеӨ–пјҢйў„жіЁеҶҢеҸҜиғҪжңүеҠ©дәҺйҒҝе…Қж„ҸеӨ–зҡ„MetaеҲҶжһҗйҮҚеӨҚпјҢжЈҖжҹҘе…¶д»–з ”з©¶дәәе‘ҳжҳҜеҗҰжӯЈеңЁиҝӣиЎҢзұ»дјјзҡ„MetaеҲҶжһҗпјҢеҸҜд»ҘиҠӮзңҒе®қиҙөзҡ„иө„жәҗгҖӮ
дәҢгҖҒж–ҮеӯҰжҗңзҙўе’Ңж•°жҚ®ж”¶йӣҶ
MetaеҲҶжһҗжңҖйҮҚиҰҒзҡ„жӯҘйӘӨд№ӢдёҖжҳҜж•°жҚ®ж”¶йӣҶгҖӮдёәдәҶиҝӣиЎҢжңүж•Ҳзҡ„ж•°жҚ®еә“жҗңзҙўпјҢйңҖиҰҒзЎ®е®ҡйҖӮеҪ“зҡ„е…ій”®иҜҚе’ҢжҗңзҙўйҷҗеҲ¶гҖӮжңүи®ёеӨҡж•°жҚ®еә“еҸҜдҫӣдҪҝз”ЁпјҲдҫӢеҰӮPubMed, Embase, PsychInfoпјүпјҢ然иҖҢпјҢз ”з©¶дәәе‘ҳйңҖиҰҒдёә他们зҡ„з ”з©¶йўҶеҹҹйҖүжӢ©жңҖеҗҲйҖӮзҡ„иө„жәҗгҖӮеҸҜд»Ҙж №жҚ®PRIMSAжөҒзЁӢеӣҫиҝӣиЎҢжҗңзҙўе№¶и®°еҪ•зӣёе…ідҝЎжҒҜпјҢиҜҘжөҒзЁӢеӣҫиҜҰз»Ҷд»Ӣз»ҚдәҶжүҖжңүйҳ¶ж®өзҡ„дҝЎжҒҜжөҒпјҲеӣҫ3пјүгҖӮ
еӣ жӯӨпјҢйҮҚиҰҒзҡ„жҳҜиҰҒжіЁж„ҸеңЁдҪҝз”ЁжҢҮе®ҡзҡ„жҗңзҙўжңҜиҜӯеҗҺеҸҚйҰҲдәҶеӨҡе°‘з ”з©¶пјҢдёўејғдәҶеӨҡе°‘з ”з©¶пјҢд»ҘеҸҠеҮәдәҺд»Җд№ҲеҺҹеӣ гҖӮжҗңзҙўжңҜиҜӯе’Ңзӯ–з•Ҙеә”иҜҘи¶іеӨҹе…·дҪ“пјҢд»ҘдҫҝиҜ»иҖ…йҮҚзҺ°жҗңзҙўгҖӮиҝҳеә”жҸҗдҫӣз ”з©¶зҡ„ж—ҘжңҹиҢғеӣҙд»ҘеҸҠиҝӣиЎҢжҗңзҙўзҡ„ж—ҘжңҹгҖӮ
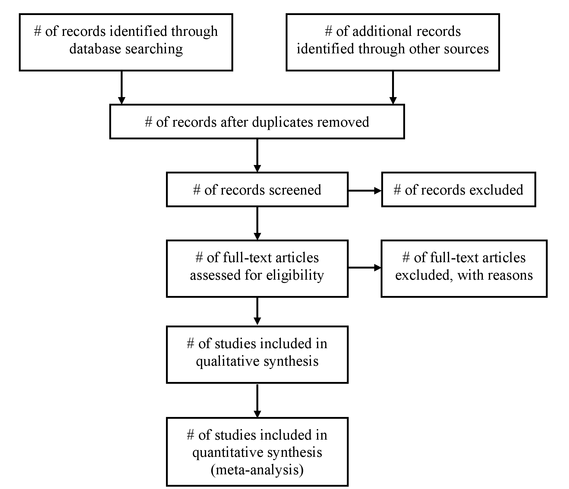
еӣҫ3 PRIMSAжөҒзЁӢеӣҫ
ж•°жҚ®ж”¶йӣҶиЎЁжҸҗдҫӣдәҶд»Һз¬ҰеҗҲжқЎд»¶зҡ„з ”з©¶дёӯ收йӣҶж•°жҚ®зҡ„ж ҮеҮҶеҢ–ж–№жі•гҖӮеҜ№дәҺзӣёе…іж•°жҚ®зҡ„MetaеҲҶжһҗпјҢж•Ҳеә”йҮҸдҝЎжҒҜйҖҡ常被收йӣҶдёәPearsonвҖҷs rз»ҹи®ЎйҮҸгҖӮйғЁеҲҶзӣёе…іжҖ§йҖҡеёёеңЁз ”究зҡ„жҠҘе‘ҠдёӯпјҢ然иҖҢпјҢдёҺйӣ¶йҳ¶зӣёе…іжҖ§зӣёжҜ”пјҢиҝҷдәӣеҸҜиғҪдјҡжү©еӨ§зӣёе…іжҖ§гҖӮжӯӨеӨ–пјҢйғЁеҲҶеҸҳйҮҸеҸҜиғҪеӣ з ”з©¶иҖҢејӮгҖӮи®ёеӨҡMetaеҲҶжһҗжҺ’йҷӨдәҶдёҺе…¶еҲҶжһҗзҡ„йғЁеҲҶзӣёе…іжҖ§гҖӮеӣ жӯӨпјҢеә”иҒ”зі»з ”з©¶дҪңиҖ…д»ҘжҸҗдҫӣзјәеӨұж•°жҚ®жҲ–йӣ¶зә§зӣёе…іжҖ§гҖӮ
жңҖеҗҺдёҖдёӘиҖғиҷ‘еӣ зҙ жҳҜжҳҜеҗҰеҢ…жӢ¬зҒ°иүІж–ҮзҢ®зҡ„з ”з©¶пјҢзҒ°иүІж–ҮзҢ®иў«е®ҡд№үдёәе°ҡжңӘжӯЈејҸеҸ‘иЎЁзҡ„з ”з©¶гҖӮиҝҷзұ»ж–ҮзҢ®еҢ…жӢ¬дјҡи®®ж‘ҳиҰҒпјҢи®әж–Үе’Ңйў„еҚ°жң¬гҖӮиҷҪ然еҢ…еҗ«зҒ°иүІж–ҮзҢ®йҷҚдҪҺдәҶеҸ‘иЎЁеҒҸеҖҡзҡ„йЈҺйҷ©пјҢдҪҶдҪңе“Ғзҡ„ж–№жі•еӯҰиҙЁйҮҸйҖҡеёёпјҲдҪҶ并йқһжҖ»жҳҜпјүдҪҺдәҺжӯЈејҸеҸ‘иЎЁзҡ„дҪңе“ҒгҖӮж— и®әеҰӮдҪ•пјҢMetaеҲҶжһҗеә”жҳҺзЎ®иҜҰз»ҶиҜҙжҳҺз ”з©¶ж–№жЎҲе’Ңж–№жі•дёӯзҡ„жҗңзҙўзӯ–з•ҘгҖӮ
дёүгҖҒеҲҶжһҗ
еҗ„з§Қе·Ҙе…·еҸҜз”ЁдәҺиҝҗиЎҢMetaеҲҶжһҗпјҢдҫӢеҰӮз»јеҗҲMetaеҲҶжһҗе’ҢSPSSиҜӯжі•ж–Ү件гҖӮеҜ№дәҺжң¬ж–ҮпјҢе°ҶдҪҝз”ЁRзҡ„вҖңmetaforвҖқе’ҢвҖңrobumetaвҖқиҪҜ件еҢ…пјҲR Development Core Team, 2015пјүгҖӮдёәдәҶиҝӣиЎҢиҜҙжҳҺпјҢе°ҶеҲҶжһҗжқҘиҮӘ16йЎ№з ”з©¶пјҲMolloyзӯү, 2014пјүMetaеҲҶжһҗзҡ„ж•°жҚ®пјҢиҜҘз ”з©¶еҲҶжһҗдәҶи°ғжҹҘиҙЈд»»еҝғе’ҢиҚҜзү©дҫқд»ҺжҖ§д№Ӣй—ҙзҡ„е…іиҒ”гҖӮ
ж•°жҚ®йӣҶеҢ…жӢ¬зӣёе…іжҖ§пјҢз ”з©¶ж ·жң¬йҮҸпјҢд»ҘеҸҠеҸҜд»ҘиҜ„дј°дёәжҪңеңЁи°ғиҠӮеҸҳйҮҸзҡ„дёҖзі»еҲ—иҝһз»ӯпјҲдҫӢеҰӮпјҢе№іеқҮе№ҙйҫ„пјүе’ҢеҲҶзұ»еҸҳйҮҸпјҲдҫӢеҰӮпјҢжүҖдҪҝз”Ёзҡ„е°ҪиҙЈжҖ§жөӢйҮҸзҡ„зұ»еһӢпјүгҖӮиҝҷдёӘMetaеҲҶжһҗзҡ„ж•°жҚ®д»ҘеҸҠеҲҶжһҗзӨәдҫӢйғҪеҢ…еҗ«еңЁmetaforеҢ…дёӯгҖӮдёҺжң¬ж–Үзӣёе…ізҡ„и„ҡжң¬иҜҰз»Ҷд»Ӣз»ҚдәҶжң¬ж–ҮжүҖиҝ°еҲҶжһҗзҡ„жүҖжңүж–№йқўпјҢиҜ»иҖ…еҸҜд»Ҙж №жҚ®иҝҷдәӣж–№йқўеҜ№зӣёе…іж•°жҚ®иҝӣиЎҢиҮӘе·ұзҡ„MetaеҲҶжһҗгҖӮ
第дёҖдёӘеҲҶжһҗжӯҘйӘӨжҳҜе°Ҷж•°жҚ®д»Һ收йӣҶиЎЁж јиҫ“е…ҘеҲ°.csvж–Ү件дёӯд»ҘдҫҝеңЁRдёӯиҝӣиЎҢеҲҶжһҗгҖӮз”ұдәҺPearsonвҖҷs rдёҚжҳҜжӯЈжҖҒеҲҶеёғзҡ„пјҢеӣ жӯӨиҝҷдәӣеҖје°ҶиҪ¬жҚўдёәFisher's zж ҮеәҰгҖӮMetaеҲҶжһҗдёӯйҖҡеёёйҮҮз”ЁдёӨз§ҚжЁЎеһӢпјҡеӣәе®ҡж•Ҳеә”жЁЎеһӢе’ҢйҡҸжңәж•Ҳеә”жЁЎеһӢгҖӮеӣәе®ҡж•Ҳеә”жЁЎеһӢеҒҮи®ҫжүҖжңүз ”з©¶йғҪжқҘиҮӘеҚ•дёҖзҡ„еёёи§ҒзҫӨдҪ“пјҢеңЁзұ»дјјжқЎд»¶дёӢиҝӣиЎҢжөӢиҜ•пјҢдёҚиҖғиҷ‘з ”з©¶зҡ„ејӮиҙЁжҖ§пјҢеҸҜиғҪдјҡй«ҳдј°з»јеҗҲж•Ҳеә”йҮҸгҖӮиҖҢйҡҸжңәж•Ҳеә”жЁЎеһӢз ”з©¶жқҘиҮӘдёҚеҗҢзҡ„зҫӨдҪ“пјҢдёәдәҶе®һзҺ°жӣҙе°‘е·®ејӮпјҢеҠ еӨ§дәҶз ”з©¶йҮҸгҖӮ
еңЁиҝӣиЎҢMetaеҲҶжһҗи®Ўз®—еҗҺпјҢеә”е°ҶFisher's zиҪ¬жҚўеӣһPearson's rпјҢд»ҘжҠҘе‘Ҡе№іеқҮзӣёе…іжҖ§е’Ң95пј…CIгҖӮеҜ№зӨәдҫӢж•°жҚ®иҝӣиЎҢеҲҶжһҗеҗҺеҸ‘зҺ°пјҢз»јеҗҲзӣёе…іжҖ§е’Ң95пј…CIиЎЁжҳҺдәҶиҙЈд»»еҝғе’ҢиҚҜзү©дҫқд»ҺжҖ§д№Ӣй—ҙеӯҳеңЁжҳҫи‘—дҪҶйҖӮеәҰзҡ„е…ізі»[r = 0.15; 95пј…CIпјҲ0.09,0.21пјүпјҢp <0.0001]гҖӮ
еӣӣгҖҒејӮиҙЁжҖ§з ”究
и§ӮеҜҹеҲ°зҡ„ж•Ҳеә”е·®ејӮжңүдёӨдёӘжқҘжәҗпјҡз ”з©¶еҶ…иҜҜе·®е’Ңж•Ҳеә”йҮҸзҡ„зңҹе®һејӮиҙЁжҖ§гҖӮеҮәдәҺMetaеҲҶжһҗзҡ„зӣ®зҡ„пјҢжҲ‘们еҜ№ж•Ҳеә”йҮҸзҡ„зңҹжӯЈејӮиҙЁжҖ§ж„ҹе…ҙи¶ЈгҖӮи®Ўз®—Q-з»ҹи®ЎйҮҸпјҢеҚіи§ӮеҜҹеҲ°зҡ„е·®ејӮдёҺз ”з©¶еҶ…ж–№е·®зҡ„жҜ”зҺҮпјҢеҸҜд»ҘжҸӯзӨәж•ҙдҪ“ејӮиҙЁжҖ§дёӯжңүеӨҡе°‘еҸҜеҪ’еӣ дәҺзңҹе®һзҡ„з ”з©¶й—ҙеҸҳеҢ–гҖӮзӣёе…ізҡ„I2з»ҹи®ЎйҮҸжҳҜиЎЁзӨәи§ӮеҜҹеҲ°зҡ„е·®ејӮжҜ”дҫӢзҡ„зҷҫеҲҶжҜ”пјҲе…¶дёӯ25пј…пјҢ50пј…е’Ң75пј…еҲҶеҲ«д»ЈиЎЁдҪҺгҖҒдёӯе’Ңй«ҳе·®ејӮпјүпјҢе…¶еҸҜд»ҘеҪ’еӣ дәҺз ”з©¶д№Ӣй—ҙзҡ„е®һйҷ…е·®ејӮпјҢиҖҢдёҚжҳҜз ”з©¶еҶ…зҡ„е·®ејӮгҖӮ
дёҺQз»ҹи®ЎйҮҸзӣёжҜ”пјҢI2зҡ„дёӨдёӘдё»иҰҒдјҳзӮ№жҳҜе®ғеҜ№жүҖеҢ…еҗ«зҡ„з ”з©¶ж•°йҮҸдёҚж•Ҹж„ҹпјҢ并且иҝҳеҸҜд»Ҙи®Ўз®—CIгҖӮTau-squaredд№ҹеҸҜз”ЁдәҺиҜ„дј°йҡҸжңәж•Ҳеә”жЁЎеһӢдёӯз ”з©¶ејӮиҙЁжҖ§зҡ„жҖ»йҮҸгҖӮеҪ“Tau-squaredдёәйӣ¶ж—¶пјҢиҝҷиЎЁжҳҺжІЎжңүејӮиҙЁжҖ§гҖӮеңЁзӨәдҫӢж•°жҚ®дёӯпјҢI2дёә61.73пј…пјҲ95пј…CI; 25.28, 88.25пјүпјҢиЎЁзӨәдёӯеәҰеҲ°й«ҳеәҰзҡ„е·®ејӮпјҢQз»ҹи®ЎйҮҸдёә38.16пјҲp = 0.001пјүпјҢTau-squaredдёә0.008пјҲ95пј…CI; 0.002, 0.038пјүгҖӮ
е°Ҫз®ЎиҝҷдәӣжөӢиҜ•жҸҗдҫӣдәҶејӮиҙЁжҖ§зҡ„иҜҒжҚ®пјҢдҪҶе®ғ们并жңӘжҸҗдҫӣе“Әдәӣз ”з©¶еҸҜиғҪдёҚжҲҗжҜ”дҫӢең°еҪұе“ҚејӮиҙЁжҖ§гҖӮBaujatеӣҫеҸҜд»ҘеҫҲеҘҪзҡ„и§ЈжһҗиҝҮеәҰдҝғжҲҗејӮиҙЁжҖ§е’Ңж•ҙдҪ“з»“жһңзҡ„з ”з©¶гҖӮеӣҫзҡ„жЁӘиҪҙиЎЁзӨәз ”з©¶ејӮиҙЁжҖ§пјҢиҖҢзәөиҪҙиЎЁзӨәз ”з©¶еҜ№ж•ҙдҪ“з»“жһңзҡ„еҪұе“ҚгҖӮиҗҪе…ҘеӣҫеҸідёҠиұЎйҷҗзҡ„з ”з©¶еҜ№иҝҷдёӨдёӘеӣ зҙ иҙЎзҢ®жңҖеӨ§гҖӮжЈҖжҹҘд»ҺзӨәдҫӢж•°жҚ®йӣҶз”ҹжҲҗзҡ„BajautеӣҫжҳҫзӨәдәҶдёүдёӘз ”з©¶еҜ№иҝҷдёӨдёӘеӣ зҙ йғҪжңүиҙЎзҢ®пјҲеӣҫ4пјүгҖӮ

еӣҫ4. з”ЁдәҺиҜҶеҲ«еҜјиҮҙејӮиҙЁжҖ§зҡ„з ”з©¶зҡ„Baujatеӣҫ
дә”гҖҒжЈ®жһ—еӣҫ
жЈ®жһ—еӣҫеҸҜд»ҘжҳҫзӨәзәіе…Ҙз ”з©¶дёӯзҡ„ж•Ҳеә”йҮҸе’ҢCIпјҢд»ҘеҸҠи®Ўз®—зҡ„з»јеҗҲж•Ҳеә”йҮҸгҖӮеӣҫ5жҳҫзӨәдәҶж №жҚ®зӨәдҫӢж•°жҚ®и®Ўз®—зҡ„жЈ®жһ—еӣҫгҖӮжҜҸйЎ№з ”з©¶йғҪз”ұдёҖдёӘзӮ№иҜ„дј°жқҘиЎЁзӨәпјҢиҜҘзӮ№иҜ„дј°з”ұж•Ҳеә”зҡ„CIйҷҗе®ҡгҖӮз»јеҗҲж•Ҳеә”йҮҸз”ұеӣҫеә•йғЁзҡ„еӨҡиҫ№еҪўиЎЁзӨәпјҢеӨҡиҫ№еҪўзҡ„е®ҪеәҰиЎЁзӨә95пј…CIгҖӮдёҺй«ҳI2е’Ңжҳҫи‘—зҡ„Qз»ҹи®ЎйҮҸдёҖиҮҙпјҢжЈ®жһ—еӣҫжҳҫзӨәдәҶејӮиҙЁжҖ§з ”究зҡ„ж ·жң¬гҖӮдёҺе…¶д»–з ”з©¶зӣёжҜ”пјҢиҫғеӨ§ж–№йҳөзҡ„з ”з©¶еҜ№з»јеҗҲж•Ҳеә”йҮҸзҡ„иҙЎзҢ®жӣҙеӨ§гҖӮеңЁйҡҸжңәж•Ҳеә”жЁЎеһӢдёӯпјҢж–№йҳөзҡ„еӨ§е°ҸдёҺCIе’Ңз ”з©¶й—ҙе·®ејӮзӣёе…ігҖӮ
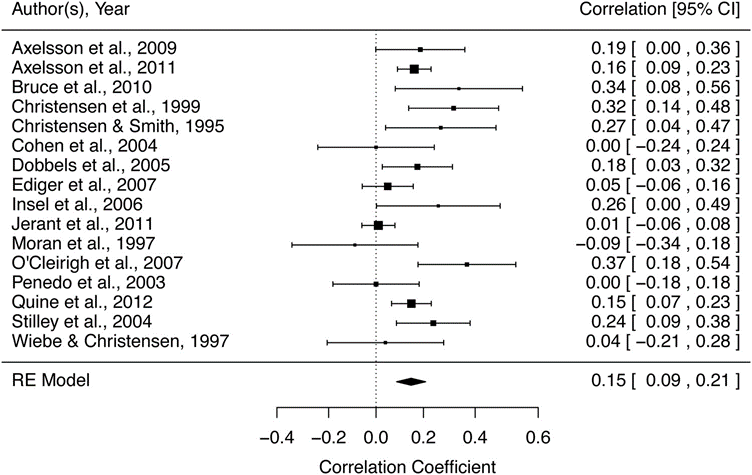
еӣҫ5. зӨәдҫӢж•°жҚ®зҡ„жЈ®жһ—еӣҫ
иҙЈд»»еҝғе’ҢиҚҜзү©дҫқд»ҺжҖ§д№Ӣй—ҙе…ізі»зҡ„зӨәдҫӢж•°жҚ®жҖ»з»“гҖӮMetaеҲҶжһҗдёӯеҢ…еҗ«зҡ„жҜҸйЎ№з ”з©¶еқҮз”ұзӮ№дј°и®ЎиЎЁзӨәпјҢиҜҘзӮ№дј°и®Ўд»Ҙ95пј…CIдёәз•ҢгҖӮз»јеҗҲж•Ҳеә”йҮҸеңЁеӣҫзҡ„еә•йғЁжҳҫзӨәдёәеӨҡиҫ№еҪўпјҢеӨҡиҫ№еҪўзҡ„е®ҪеәҰиЎЁзӨә95пј…CIгҖӮ
е…ӯгҖҒеҸ‘иЎЁеҒҸеҖҡ
еҸ‘иЎЁеҒҸеҖҡжҳҜдёҖз§ҚзҺ°иұЎпјҢеҚіе…·жңүжӣҙејәж•Ҳеә”йҮҸзҡ„з ”з©¶жӣҙжңүеҸҜиғҪиў«еҸ‘表并йҡҸеҗҺиў«зәіе…ҘMetaеҲҶжһҗгҖӮжјҸж–—еӣҫжҳҜдёҖз§ҚеҸҜи§ҶеҢ–е·Ҙе…·пјҢз”ЁдәҺжЈҖжҹҘMetaеҲҶжһҗдёӯжҪңеңЁзҡ„еҸ‘иЎЁеҒҸеҖҡгҖӮжјҸж–—зәҝд»Ҙз»јеҗҲж•Ҳеә”йҮҸдёәдёӯеҝғпјҢз”ұеһӮзӣҙзәҝиЎЁзӨәпјҢиҝҷдәӣзӮ№еә”зӯүж•Ҳең°еҲҶеёғеңЁжјҸж–—зәҝзҡ„дёӨдҫ§пјҲеӣҫ6AпјүгҖӮеӣҫ6BдҪҝз”Ёд»ҺзӨәдҫӢж•°жҚ®йӣҶдёӯ移йҷӨдёүдёӘз ”з©¶зҡ„жЁЎжӢҹжқҘиҜҙжҳҺжјҸж–—зҡ„дёҚеқҮеҢҖжҖ§пјҢдёәеҸ‘иЎЁеҒҸеҖҡжҸҗдҫӣдәҶиҜҒжҚ®гҖӮ
еҰӮжһңжңүеҸ‘иЎЁеҒҸеҖҡзҡ„иҜҒжҚ®пјҢеҸҜд»ҘдҪҝз”Ёдҝ®еүӘе’ҢеЎ«е……ж–№жі•гҖӮиҜҘж–№жі•еҒҮи®ҫжјҸж–—еӣҫдёҚеҜ№з§°жҳҜз”ұдәҺеҸ‘иЎЁеҒҸеҖҡпјҢйҖҡиҝҮе°ҶвҖңзјәеӨұвҖқз ”з©¶еҪ’з»“дёәеўһеҠ жјҸж–—еӣҫеҜ№з§°жҖ§жқҘи°ғж•ҙMetaеҲҶжһҗпјҲеӣҫ6CпјүгҖӮиҝҷз§Қжӣҙж–°зҡ„дј°з®—з ”з©¶зҡ„MetaеҲҶжһҗдёҚеә”з”ЁдәҺеҪўжҲҗз»“и®әпјҢеӣ дёәиҝҷдәӣдёҚжҳҜзңҹжӯЈзҡ„з ”з©¶пјҢеҸӘжҳҜдёәдәҶе№іиЎЎдёҚеҜ№з§°зҡ„жјҸж–—еӣҫгҖӮеӣҫ5AпјҢCзҡ„жҜ”иҫғиҜҙжҳҺдәҶиҝҷдёҖзӮ№пјҢеӣ дёәиҜҘж–№жі•иў«и®ҫи®Ўдёәд»…йҖҡиҝҮеҲӣе»әзҺ°жңүз ”з©¶зҡ„й•ңеғҸжқҘиҝ‘дјјзјәеӨұзҡ„з ”з©¶гҖӮ

еӣҫ6. жјҸж–—еӣҫд»ҘиҜҙжҳҺеҸ‘еёғеҒҸеҖҡ
жјҸж–—еӣҫпјҲAпјүеҢ…жӢ¬Molloyзӯүдәәзҡ„жүҖжңү16йЎ№з ”з©¶пјҲ2014пјүгҖӮ иҜҘеӣҫзӨәеҮәдәҶеҜ№з§°жҖ§пјҲеҚіпјҢзӮ№иҗҪеңЁз»јеҗҲж•Ҳеә”йҮҸзҡ„дёӨдҫ§пјүгҖӮжјҸж–—еӣҫпјҲBпјүжЁЎжӢҹдәҶ移йҷӨMolloyзӯүдәәж•°жҚ®йӣҶдёӯзҡ„дёүз§Қе°Ҹж•Ҳеә”е’ҢеӨ§ж ҮеҮҶиҜҜе·®зҡ„з ”з©¶гҖӮжғ…иҠӮдёҚеҶҚжҳҜеҜ№з§°зҡ„пјҢиҜҒжҳҺдәҶеҸ‘иЎЁеҒҸеҖҡзҡ„иҜҒжҚ®гҖӮжјҸж–—еӣҫпјҲCпјүдҝ®еүӘе’ҢеЎ«е……зЁӢеәҸдјҡеҜјиҮҙзјәеӨұзҡ„з ”з©¶пјҲз©әеҝғеңҶеңҲпјүпјҢд»ҘеҲӣе»әжӣҙеҠ еҜ№з§°зҡ„жјҸж–—еӣҫгҖӮ
дёғгҖҒи°ғиҠӮеҸҳйҮҸеҲҶжһҗ
и°ғиҠӮеҸҳйҮҸжңүеҠ©дәҺи§ӮеҜҹеҲ°дёҖдәӣе·®ејӮгҖӮеӣ жӯӨпјҢеҸҜд»ҘиҝӣиЎҢи°ғиҠӮеҸҳйҮҸеҲҶжһҗд»ҘзЎ®е®ҡејӮиҙЁжҖ§зҡ„жқҘжәҗд»ҘеҸҠиҝҷеҜ№з ”究д№Ӣй—ҙи§ӮеҜҹеҲ°зҡ„ж•Ҳеә”йҮҸзҡ„еҸҳеҢ–жңүеӨҡеӨ§иҙЎзҢ®гҖӮи°ғиҠӮеҸҳйҮҸеҸҜд»ҘжҳҜиҝһз»ӯеҸҳйҮҸжҲ–еҲҶзұ»еҸҳйҮҸгҖӮдҫӢеҰӮпјҢеҸҜд»ҘдҪҝз”ЁMetaеӣһеҪ’жЁЎеһӢиҝӣиЎҢи°ғиҠӮеҸҳйҮҸеҲҶжһҗпјҢд»ҘжЈҖжҹҘе№іеқҮе№ҙйҫ„еҜ№MolloyзӯүдәәпјҲ2014пјүж•°жҚ®йӣҶзҡ„еҪұе“ҚгҖӮи®Ўз®—иҜҘеҲҶжһҗиЎЁжҳҺпјҢе№ҙйҫ„жІЎжңүи°ғиҠӮж•Ҳеә”[Q(1)= 1.43пјҢp = 0.23]гҖӮ
еҸҰеӨ–пјҢеҸҜд»ҘжЈҖжҹҘж–№жі•еӯҰиҙЁйҮҸзҡ„и°ғиҠӮж•Ҳеә”гҖӮеҜ№е®һдҫӢж•°жҚ®зҡ„еҲҶжһҗиЎЁжҳҺпјҢж–№жі•еӯҰиҙЁйҮҸд№ҹжІЎжңүзј“е’Ңзӣёе…іжҖ§[Q(1)= 0.64пјҢp = 0.42]гҖӮ然иҖҢпјҢи°ғиҠӮеҸҳйҮҸеҲҶжһҗиЎЁжҳҺеҸҳйҮҸеҲҶзұ»жҳҜеҗҰз ”з©¶жҺ§еҲ¶еҸҳйҮҸпјҲжҳҜ/еҗҰпјүжҳҜдёҖдёӘйҮҚиҰҒзҡ„и°ғиҠӮиҖ…[Q(1)= 20.12пјҢp <0.0001]гҖӮиҷҪ然еҸҜиғҪеӯҳеңЁе…¶д»–жңӘжҳҺзЎ®зҡ„з ”з©¶ејӮиҙЁжҖ§жқҘжәҗпјҢдҪҶж•°жҚ®иЎЁжҳҺжҺ§еҲ¶з ”究дёӯзҡ„еҸҳйҮҸжңүеҠ©дәҺж•ҙдҪ“и§ӮеҜҹеҲ°зҡ„ејӮиҙЁжҖ§гҖӮ
е…«гҖҒд»ҺеҚ•дёӘз ”з©¶дёӯиҺ·еҫ—еӨҡз§Қж•Ҳеә”йҮҸзҡ„и®Ўз®—
еҰӮжһңд»ҺеҗҢдёҖз ”з©¶дёӯ收йӣҶдәҶеӨҡз»„ж•°жҚ®пјҢеҲҷз”ұдәҺз»ҹи®Ўдҫқиө–жҖ§й—®йўҳпјҢеә”иҖғиҷ‘иҝҷдәӣз ”з©¶дёӯж•Ҳеә”йҮҸзҡ„еҶ…йғЁз»ҹи®Ўдҫқиө–жҖ§гҖӮжңҖзӣҙжҺҘзҡ„ж–№жі•жҳҜд»…дҪҝз”Ёйў„е…ҲжҢҮе®ҡзҡ„ж ҮеҮҶ收йӣҶжҜҸдёӘз ”з©¶зҡ„ж•Ҳеә”йҮҸгҖӮжҲ–иҖ…пјҢеҸҜд»ҘиҒҡеҗҲж•Ҳеә”йҮҸпјҲеҸӮи§Ғ'MAc'RеҢ…дёӯзҡ„'Agg'еҠҹиғҪпјүгҖӮ然иҖҢпјҢеҰӮжһңжІЎжңүжҠҘе‘Ҡз ”з©¶еҶ…зӣёе…іжҖ§пјҢз ”з©¶дәәе‘ҳеҝ…йЎ»дј°и®Ўйў„жңҹзҡ„зӣёе…іжҖ§ж°ҙе№ігҖӮ
Robustж–№е·®иҜ„дј°пјҲRVEпјүеҸҜд»ҘеңЁдёҚдәҶи§Јз ”з©¶еҶ…зӣёе…іжҖ§зҡ„жғ…еҶөдёӢи§ЈйҮҠйқһзӢ¬з«Ӣж•Ҳеә”гҖӮдёәдәҶиҜҙжҳҺдҪҝз”ЁRVEеӨ„зҗҶеӨҡз§Қж•Ҳеә”йҮҸпјҢжҲ‘们еҲӣе»әдәҶдёҖдёӘж–°зҡ„жЁЎжӢҹж•°жҚ®йӣҶпјҢе…¶дёӯеүҚдёүдёӘз ”з©¶жқҘиҮӘж ·жң¬ж•°жҚ®йӣҶпјҢе°ұеғҸе®ғ们жҳҜд»ҺдёҖйЎ№з ”з©¶жҠҘе‘Ҡзҡ„дёүз§Қж•Ҳеә”йҮҸдёҖж ·гҖӮдҪҝз”ЁRVEеҲҶжһҗжҳҫзӨәз»ҹи®ЎеӯҰдёҠжҳҫи‘—зҡ„зӮ№дј°и®Ў[0.15; 95пј…CI(0.08,0.22)пјҢp = 0.001]гҖӮ
д№қгҖҒж•°жҚ®и§ЈйҮҠе’ҢжҠҘе‘Ҡ
MetaеҲҶжһҗзҡ„жңҖеҗҺдёҖжӯҘжҳҜж•°жҚ®и§ЈйҮҠе’ҢеҶҷдҪңгҖӮPRISMAжҢҮеҚ—жҸҗдҫӣдәҶдёҖд»ҪеҲ—иЎЁпјҢе…¶дёӯеҢ…жӢ¬жҠҘе‘ҠMetaеҲҶжһҗж—¶еә”еҢ…жӢ¬зҡ„жүҖжңүйЎ№зӣ®гҖӮйҒөеҫӘжӯӨеҲ—иЎЁе°ҶжңүеҠ©дәҺзЎ®дҝқжҠҘе‘ҠMetaеҲҶжһҗзҡ„иҙЁйҮҸпјҢ并жңүеҠ©дәҺж”№иҝӣеҜ№зЁҝ件зҡ„иҜ„дј°гҖӮеҗҢж—¶иҝҳеҸҜд»ҘжҸҗдҫӣз”ЁдәҺеҲҶжһҗзҡ„Rи„ҡжң¬дҪңдёәиЎҘе……жқҗж–ҷд»Ҙеё®еҠ©еҶҚзҺ°жҖ§гҖӮ
жң¬ж–Үзҡ„зӣ®зҡ„жҳҜжҸҗдҫӣдёҖдёӘйқһжҠҖжңҜжҖ§зҡ„е…Ҙй—Ёд№ҰпјҢз”ЁдәҺжҢүз…§й»„йҮ‘ж ҮеҮҶжҢҮеҚ—иҝӣиЎҢзӣёе…іж•°жҚ®зҡ„MetaеҲҶжһҗгҖӮMetaеҲҶжһҗжҳҜдёҖз§Қжңүж•Ҳзҡ„ж•°жҚ®еҗҲжҲҗж–№жі•пјҢеҚідҪҝеҸӘйңҖиҰҒдёӨеҲ°дёүйЎ№з ”з©¶пјҢд№ҹеҸҜд»Ҙжңүж•Ҳең°жҸҗй«ҳз»ҹи®ЎзІҫеәҰгҖӮ
жң¬ж–ҮеҲ©з”ЁеҸҜиҮӘз”ұи®ҝй—®зҡ„иҪҜ件演зӨәдәҶMetaеҲҶжһҗзҡ„жҜҸдёӘеҲҶжһҗжӯҘйӘӨпјҢе…¶дёӯиЎҘе……и„ҡжң¬жҸҗдҫӣдәҶжү§иЎҢжң¬ж–ҮжүҖиҝ°еҲҶжһҗзҡ„еҝ…иҰҒд»Јз ҒгҖӮиҝҳи®Ёи®әдәҶж•°жҚ®еҸҜи§ҶеҢ–зҡ„ж–№жі•пјҢиҜҶеҲ«еҸҜиғҪиҝҮеәҰеҪұе“Қж ·жң¬ејӮиҙЁжҖ§зҡ„з ”з©¶пјҢд»ҘеҸҠз»„еҗҲжқҘиҮӘдёӘдҪ“з ”з©¶зҡ„еӨҡз§Қж•Ҳеә”йҮҸгҖӮиҝҳжҸҸиҝ°дәҶе…ідәҺеҸ‘иЎЁеҒҸеҖҡе’Ңи°ғиҠӮеҸҳйҮҸеҲҶжһҗзҡ„MetaеҲҶжһҗж•°жҚ®и§ЈйҮҠгҖӮ
еҸӮиҖғиө„ж–ҷпјҲеӣҫзүҮеқҮжқҘиҮӘж–ҮзҢ®пјүпјҡ
From pre-registration to publication: a non-technical primer for conducting a meta-analysis to synthesize correlational data;
Conscientiousness and medication adherence: a meta-analysis.
вҖў END вҖў

